
摘 要: 由于信息化程度不断提高, 军事通信网变得日趋复杂, 目前现有的依靠人力的传统运维保障方式逐渐力不从心, 尤其是在分析海量运维数据, 以及提高运维问题的效率方面。随着人工智能时代的到来, 网络运维领域也迎来了新的方式—AIOps。现提出一种将AIOps应用于军事通信网智能运维平台的建设思路, 通过机器学习算法, 以期减少人力的同时大幅提高网络运维整体效率。
关键词: 网络运维; 海量数据处理; AIops; 机器学习;
0 、引言
随着信息时代的来临, 现代战争已经开始朝着高烈度、技术集成、精确化方向发展, 而军事通信网作为这一切的基础, 其重要性不言而喻。在信息化强军的大背景下, 对网络的不断升级以及现代化改造使得网络变得日趋复杂, 对网络的依赖性、可靠性也有了更高的要求, 随之而来的运维保障需求也呈指数增长。面对不断增加的网络设备, 如何保障通信网络畅通以及设备的正常运行成为首要问题。网络设备硬件的快速发展已经极大地提高了应用程序的可靠性, 但是在军事通信网系设备中仍然存在大量的硬件故障以及潜在的故障, 这将危及整个指挥信息系统的正常运行。这些设备通常都是7×24小时不间断运行, 对这些系统的持续监控就变得至关重要。从数据分析的角度来看, 这意味着对大量设备数据的不间断监测, 以便检测潜在的故障或异常。由于问题的大规模性, 通过人工来对这个数据的监控实际上是不可行的。然而通过可自主学习和不断迭代的智能机器算法, 可以实现“越用越准确”的事故根因定位和事故预测的运维能力[1], 并且在创建更高智能、更快效率、更低成本、更加创新的智能运维管理模式的同时, 运维保障方向也开始向着机器算法模型的持续迭代与改进。
1、 军事通信网运维存在的问题
(1) 报警数据过于庞大
网络的不断升级改造同时带来的是海量的运维数据, 受限于军内运维人员编制、人员数量、技术水平、运维人员精力等因素, 并且对报警影响范围和程度全局性把控较弱, 往往忽略低级别报警, 而低级别报警并非完全无用, 如果说高级别报警反映了特殊事件、重大事件, 那么这些低级别报警则综合反映了网络环境的总体运行态势, 在所有报警中, 低级别报警数量更多、占比更高, 其中蕴含了整体网络运行趋势的同时也存在隐患, 但目前尚缺乏针对报警数据的综合分析能力。

(2) 报警模式过于传统
传统的依靠静态阈值的报警模式已显得越来越乏力, 单纯的针对被监控网系设备采取设置固定报警阈值的运维方法, 即“一刀切”、“非黑 (报警) 即白 (正常) ”的报警方式往往会产生大量的误报, 对于瞬息万变的网络状态无能为力, 无法针对变化的指标进行准确地把控。
(3) 报警分析不够智能
目前仅能够对已发生或已造成的损失进行事后处理, 往往过于被动, 无法提前对积累的隐患进行有效的分析和判断, 错过了避免损失的最佳整改时期, 传统的运维能力无法对故障做出事前预测。
(4) 报警定位不够精确
网络环境的不断升级改造使得整个体系变得异常复杂, 潜藏的微小组件故障很可能引发一连串的异常响应, 如同“蝴蝶效应”一般, 引发大规模的系统之间的海量报警, 形成报警风暴, 受限于运维人员水平及应急响应机制, 往往是哪里有报警处理哪里, 耗费大量的精力来处理旁系报警, 而忽略了最核心的潜藏故障, 导致报警反复发生, 治标不治本。目前尚缺乏从表面故障快速追踪到本质根源的能力。
2、 网络运维的发展
传统的网络运维大致经历了人工运维、工具化运维、自动化运维 (DevOps) 和智能化运维 (AIOps) 几个阶段, 这里的AIOps是指Artificial Intelligence for IT Operations, 最早由Gartner[2]定义为采用人工智能算法 (AI和机器学习) , 是利用机器解决已知的问题和潜在的运维问题的一种技术解决方案。
智能运维AIOps是ITOA/ITOM演进的最终形态, 有别于传统运维策略。通过建立基于机器学习算法的智能化运维分析平台, 在人为容许的范围内进行自主分析和决策的技术, 将数据、算法和模型用于网络运维任务和流程中, 实现从“基于专家经验”到“基于机器学习”的转变, 在动态变化的复杂场景条件下, 通过智能化运维平台能够做出高效准确的决策判断。对于海量监控报警数据聚合、动态异常监测、故障预警、故障预测等基于海量运维数据做出分析判断, AIOps将具备极大的优势, 在大幅减轻运维人员负担的同时提高运维效率和准确性。据Gartner预测, AIOps的全球部署率将从2017年的10%增加到2020年的50%。AIOps继承了自动化和DevOps的优点, 利用机器学习提升智能性和效率[3]。
3 、智能运维AIOps的应用研究
3.1、 基于大数据的智能运维平台
通过前面的分析可构建统一的运维数据分析平台, 平台采用Paa S (Platform as a Service) 的设计思路, 整合各功能模块, 并通过可视化工具进行展示, 本智能运维平台需要具有“模块化、智能化、可视化”三个特征:
“模块化”是指运维工具系统区别于传统方式的黑盒设计, 是按照不同的功能建设多个独立的运维功能模块, 既基于“平台 模块”的方式集约化设计, 通过一个统一的平台承载不同领域的运维工具的松耦合应用模块, 以达到统一控制、灵活删改与自由拓展的目的。
“智能化”要求运维平台具有智能化的数据处理、存储和分析能力, 并能通过对运维场景的不断积累和机器学习, 具有在容许的范围内进行自主分析和决策能力。
“可视化”指的是将各模块的分析处理结果统一进行展示, 以全局的形式呈现给运维人员, 方便其进行决策。由于本模块不是智能运维的核心部分, 故不做详细介绍。
智能运维平台功能架构遵循分布式、实时性、大数据量、水平扩展等设计原则, 各个模块的功能说明如图1所示:
图1 模块功能
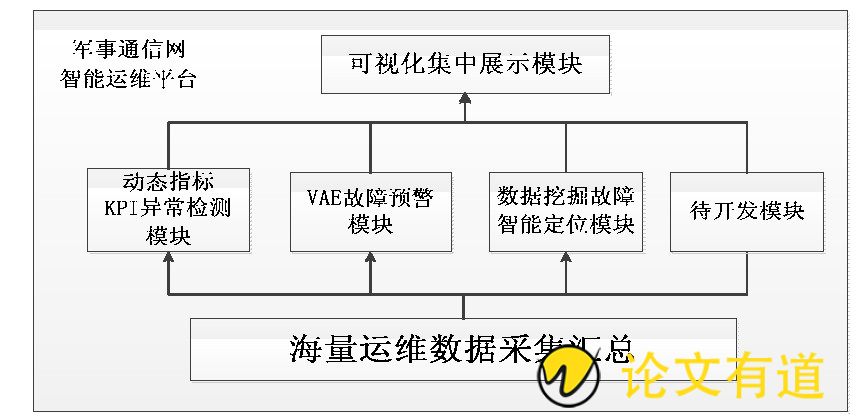
(1) 海量运维数据采集汇总:这是一切运维功能的基础, 通过将现有监控平台的性能和报警数据的集成方式, 完成原始数据的集中汇聚和纳管。将数据进行清洗、聚合, 去除大量重复和无效报警。统一运维数据, 形成数据资产, 为后续的智能分析模块提供数据支撑。
(2) 基于动态指标的KPI异常检测:通过使用智能算法对运维历史监控指标KPI进行学习, 来克服传统的静态阈值设置的烦琐且误报率大的工作缺陷, 可通过分组的方式来确定管理监控的范围从而代替针对某一台主机的单独设置, 对分组中的所有设备进行观察指标统一指标基线设置。
(3) 基于VAE的故障预警:基于原始KPI数据, 通过对特定故障场景的历史指标和报警学习, 借助机器学习算法来预测发生故障的概率, 从而达到提前预警的目的。
(4) 基于数据挖掘的故障定位:通过对业务各个节点 (Web服务器、数据库等) 的监控指标和报警事件关联性分析, 在指标产生异常波动的时结合相关权值和故障信息聚合, 将不同节点的不同指标事件的相关权值进行排名, 快速分析出某节点的指标和事件的根本原因。
3.2 、海量运维数据采集汇总
运维数据采集汇总, 需要将平台监控所采集到的各类数据指标进行融合管理, 关联规则定义, 对重复事件或者定义的事件进行聚合, 包括数据清洗、标准化和统一存储, 为后续分析处理提供数据源。在数据汇聚上首先将异常指标数据进行整合, 建立故障数据关联关系, 根据配置信息确定指标关联全集, 然后利用指标波动分析算法对其进行剪枝, 去掉无波动关联的指标。
在数据处理上使用智能处理引擎, 提升数据处理效率;在数据分析上则采用分析学习引擎, 通过算法、模型来实现对故障的具体分析:统一采集控制模块不关注底层的通讯和调度技术, 主要负责提供各运维工具和被管设备资源之间联络通讯的统一通道, 并通过模块和插件的技术让各运维工具自由扩展采控能力, 并组织成策略下发给相应代理, 对结果数据进行处理, 即可完成机器数据采集、配置变更发布和资源操作控制。
图2 海量运维数据采集汇总
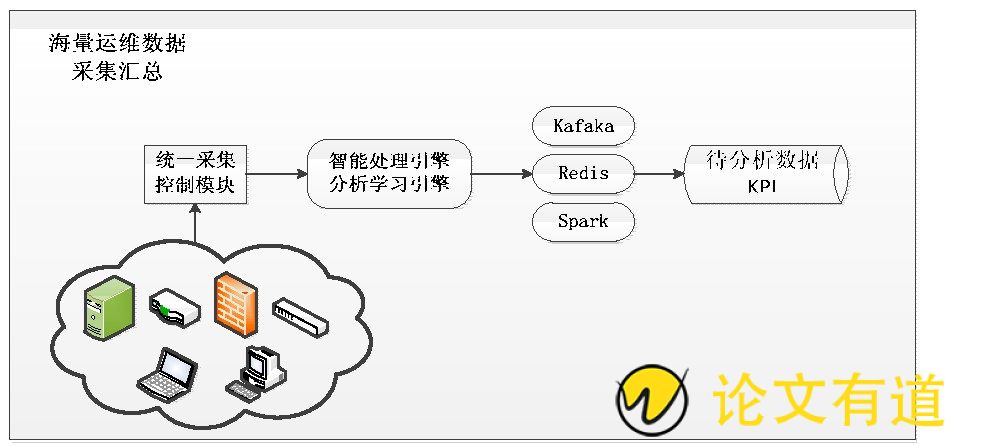
Kafka是一种快速、可扩展的、设计内在就是分布式的, 分区的和可复制的提交日志服务[4]。Kafka是一种高吞吐量的消息中间件系统, 整体架构非常简单, 是显式分布式架构, 客户端和服务器端的通信, 是基于简单, 高性能, 且与编程语言无关的TCP协议。Redis是一种开源的高性能键值对数据库, 它通过提供多种键值数据类型来适应不同场景下存储需求[5], 并借助许多高层级的接口使其可以胜任如缓存、队列系统等不同的角色。Redis数据库中的所有数据都存储在内存中, 由于内存的读写速度远快于磁盘, 因此Redis在性能上对比其他基于磁盘存储的数据库有非常明显的优势。所以平台在数据缓冲层采用了Kafaka、Redis技术, 实现产品各层、各模块之间的消息通信与本地数据缓存具备优秀的运行性能。
Spark为我们提供了一个全面、统一的框架, 用于管理有着不同性质 (文本数据、图表数据等) 的数据集和数据源 (批量数据或实时的流数据) 的大数据处理的需求, 并且处理速度远远高于Hadoop。Spark有着优秀的技术架构, 在产品分布式计算、并行计算方面具有良好的扩展性、优秀的运行性能, 可支持海量计算场景。所以在数据处理层采用了Spark技术。
因此, 数据存储以及处理方面采用Kafaka、Redis Spark技术, 形成待分析数据资源库, 为后续分析做好准备。
3.3、 基于动态指标的KPI异常检测
图3 动态指标KPI异常检测模块
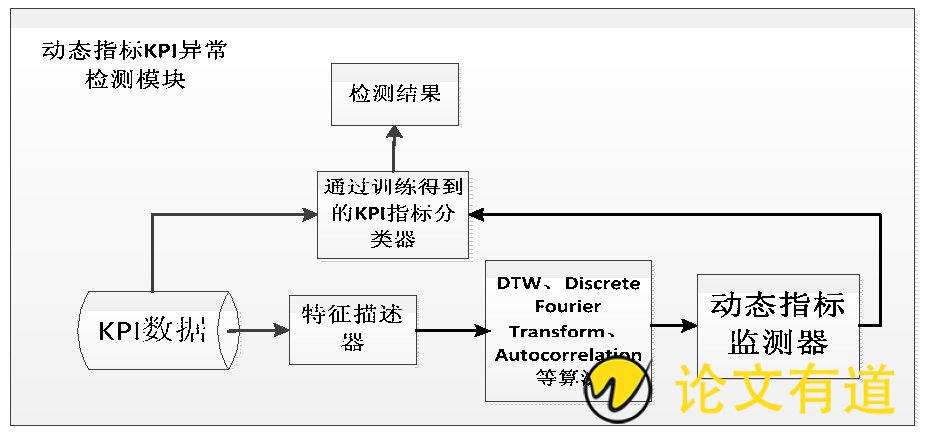
总体架构如上图所示, 首先对要检测的KPI进行特性描述, 通过分析历史数据, 提取KPI关键特征, 如周期长度、周期偏移、抖动程度, 作为KPI的特性, 指导后续检测器和参数配置。并通过DTW、Autocorrelation、Discrete Fourier Transform等算法。利用动态规划算法, 找到不同时间段数据间的偏移程度, 即可以识别曲线周期偏移程度。
动态指标监测器通过对历史监控指标进行学习, 使用智能算法来克服传统的静态阈值设置的烦琐工作缺陷, 监测器无须针对一台主机单独设置, 可通过分组的方式来确定管理监控的范围, 对分组中的所有设备进行观察指标统一设置基线。可以选择范围内特点的主机, 查看样本的基线趋势匹配度, 进行人工干预算法的调优。如针对数据中心的分组, 对数据中心的所有主机设定动态指标、针对每个业务应用的分组, 对业务所属主机批量设置动态指标。
将提取得到的KPI特性用于配置后续监测器的选择和参数设置, 监测器将提取KPI的各种时序特征, 利用这些特征训练分类器 (一般需要2-3周历史数据) , 常用的监测器包括:时序分解算法、三阶指数平滑Holt-winters、EWMA、WMA、差分、小波分析等。分类器训练完成后, 可以对实时数据进行异常检测, 达到动态检测的目的。
3.4、 基于VAE的故障预警
故障预警需要对历史的监控指标和异常KPI数据进行学习来实现功能。具体地, 将该问题转化为多KPI异常检测的问题, 对某一监控实体收集多种监控指标, 然后利用深度学习算法VAE (Variational Auto-Encoder) 对多KPI进行建模, 从而描绘机器的正常行为, 识别出正常情况下多KPI的联动模式。然后检测未来多KPI违反历史规律的行为, 来进行预警。为了提高故障早期预测的精准性, 首先将故障按照一定的管理维度进行集中化展示, 模块提供了基于场景化的分类管理手段, 建立对应的报警处理规则和机器学习算法, 来进行报警的提前判断和预警。
异常预警算法分为五个步骤:
图4 VAE故障预警模块
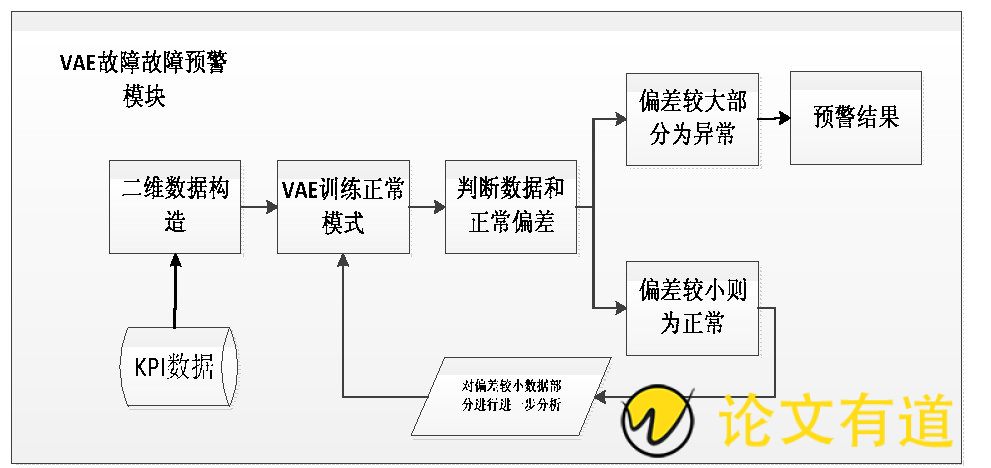
(1) 将KPI原始数据进行场景化分类, 精细化处理;
(2) 将多KPI数据构造为2维数组, 作为VAE的输入;
(3) VAE中采用卷积和反卷积网络结构, 训练得到多KPI数据的正常模式;
(4) 检测数据中和正常模式偏离较大的部分作为异常并输出预警结果;
(5) 检测数据中和正常模式偏离较小的部分作为正常, 并作进一步分析。
图5 算法模型
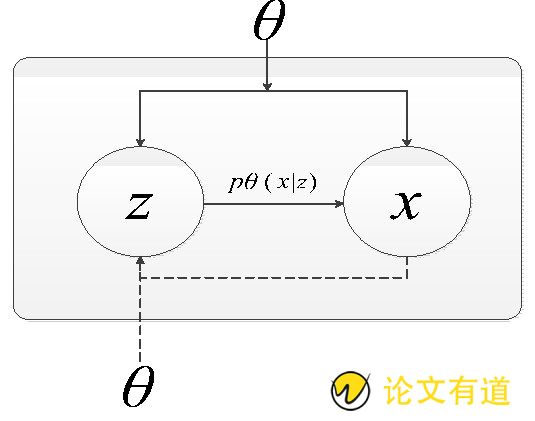
其中核心算法VAE是一种使用了变分推理方法的深度贝叶斯网络, 同时又符合自动编码器的基本结构。z表示隐变量;x表示原始数据;θ表示解码网络层参数;N表示当参数θ保持不变时, 能够从z和x中采样的次数。pθ (x|z) 表示编码网络层参数通过降维强迫多条KPI曲线将关联特性编码在分布p (z) 中采样z, 通过神经网络实现pθ (x|z) 自动生成数据, 非常适用于挖掘前述多KPI之间的联动关系, 亦可通过Kullback-Leibler散度表示分布模型间的距离[6]来提高精度, 从而实现多KPI的反常行为检测, 实现故障预警。
3.5、 基于数据挖掘的故障定位
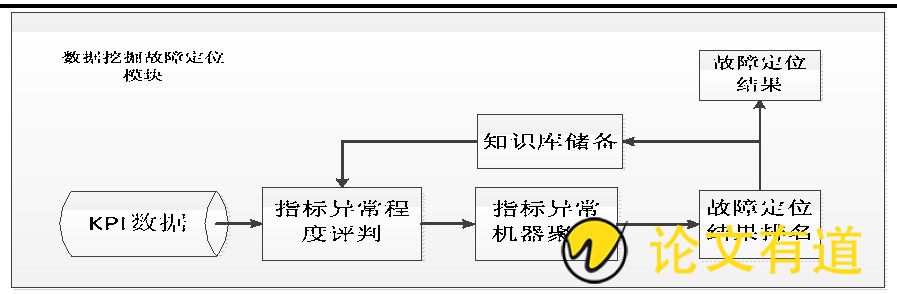
当运维出现故障时, 经常要排查业务所依赖的模块和服务器是否有问题, 每种业务都由一系列模块或中间件 (如Web服务器、数据库等) 组成, 这些模块部署在不同机房的不同服务器上, 每台服务器又有大量不同的监控指标, 但人工排查大量指标耗时长、效率低、也难以保证全面。本模块有四个主要部分构成:异常指标程度评判、指标异常机器聚类、故障定位结果排名和知识库储备。
对扫描全部模块和服务器指标产生的KPI数据, 首先评判海量异常指标程度, 接下来可以利用模糊KNN等概率密度估计算法快速对异常的机器和指标进行聚类, 将零散的结果汇总呈现, 更容易发现问题;最后对结果按照异常程度进行排序, 排名靠前则故障嫌疑越大, 为故障定位提供方向, 并为快速止损提供建议。建立基于服务的路径拓扑图, 通过故障可视化判别可能的故障根源, 并提供可视化事件时间线图, 分析故障的前后时间, 发生或发生中的事件, 展示开始结束时间以及持续时长, 以及日志、历史曲线等, 将故障推理和判别过程转化为知识库作为储备, 让分析更加有效和快捷。
图6 数据挖掘故障定位模块
4 、总结
本文介绍了应用于军事通信网的智能运维平台研究, 以大数据分析、数据挖掘和机器学习为核心的模块化智能运维体系架构, 以达到减轻运维人员负担、大幅提高运维效率的目的。对军事通信网的智能化运维做出了一些探索性研究。但就目前业内而言, AIOps这项新技术还存在诸多技术难题等待解决, 包括机器学习算法的精确性和时效性还有待提高, 今后将针对以上问题进行更加持续深入的研究。我们的终极目标是基于机器学习算法的全局智能自恢复功能的设计和实现, 实现真正的脱离人工、自行查找解决问题, 从而达到真正的完全自主化的运维。
参考文献
[1] 标题:2018Linked See灵犀首届AIOps峰会首发Linked AIOps-LinkedSee-通信行业-hc360慧聪网http://info.tele.hc360.com/2018/05/221129593068.shtml.
[2] Gartner.https//blogs.gartner.com/andrew-learner/2017/08/09/aiops-platforms/Liu D, Zhao Y, Xu H, et al.Opprentice:Towards Practical and Automatic Anomaly Detection Through Machine Learning[C]//Proceedings of the 2015 Internet Measurement Conference.New York:ACM Press, 2015:211-224.
[3] 标题:kafka与zookeeper简介-z_hong7-博客园https://www.cnblogs.com/leaf-7/p/5310054.html.
[4] 标题:Java开发大型互联网数据库Redis介绍与使用之实战剖析:https://baijiahao.baidu.com/s?id=1582287350403392354&wfr=spider&for=pc.
[5] Goldberger J, Gordon S, Greenspan H.An efficient i--mage similarity measure based on approximations of KL-Di v-ergence between two Gaussian mixtures[C]//IEEE Internatio-nal Conference on Computer Vision (ICCV) , 2003:487-493.